OmniHuman-1: Rethinking the Future of Human Animation
OmniHuman-1 is a groundbreaking one-stage conditioned human animation framework that transforms a single human image into a lifelike video using multimodal motion signals. Developed by a research team at Bytedance, this innovative model leverages audio, video, or a combination of both to create remarkably realistic animations, paving the way for numerous applications in digital media and beyond.
OmniHuman: Overview and Technical Breakthroughs
OmniHuman-1 introduces a novel end-to-end multimodality-conditioned approach that overcomes traditional limitations caused by scarce high-quality data. By implementing a mixed training strategy, the model efficiently scales with diverse input types—whether portrait, half-body, or full-body images—delivering high fidelity in motion, lighting, and texture.
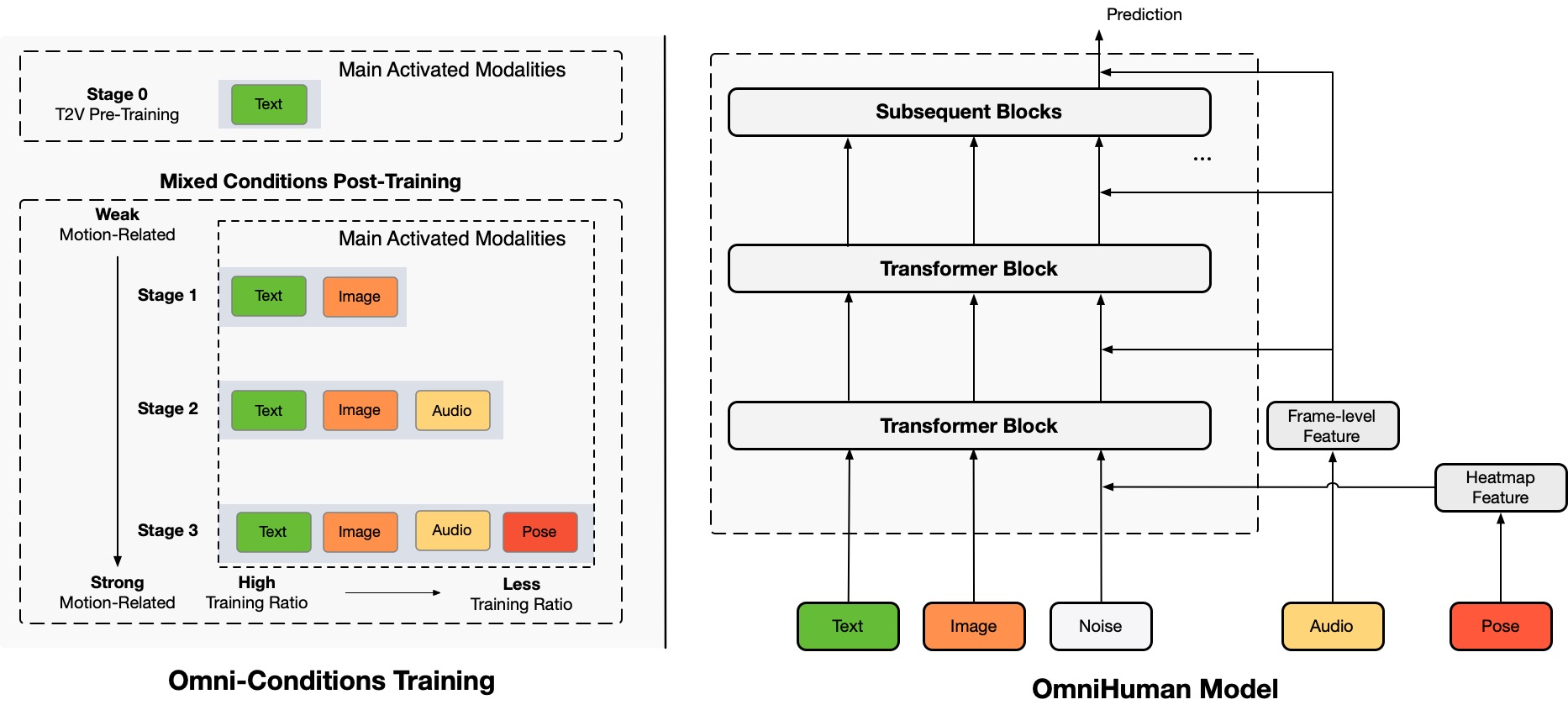
OmniHuman: The Technology Behind the Model
At its core, OmniHuman-1 integrates multiple conditioning signals to drive animation:
- Audio-Driven Motion: Captures subtle speech gestures and synchronizes lip movements.
- Video-Driven Cues: Mimics complex actions by referencing specific video inputs.
- Combined Modalities: Harmonizes audio and video inputs for enhanced realism.
This comprehensive conditioning ensures that even weak signals—especially audio—are effectively transformed into natural human motions.
OmniHuman: Generated Videos
OmniHuman supports various visual and audio styles. It can generate realistic human videos at any aspect ratio and body proportion (portrait, half-body, full-body all in one), with realism stemming from comprehensive aspects including motion, lighting, and texture details. Below are demo videos showcasing these capabilities:
OmniHuman: Talking
OmniHuman can support input of any aspect ratio in terms of speech. It significantly improves the handling of gestures—a challenge for existing methods—and produces highly realistic results. The following videos illustrate how OmniHuman processes speech and synchronizes gestures seamlessly:
OmniHuman: Diversity
In terms of input diversity, OmniHuman supports cartoons, artificial objects, animals, and challenging poses, ensuring that the generated motion characteristics match each style's unique features. The diverse outputs are demonstrated in the following videos:
OmniHuman: More Halfbody Cases with Hands
Additional examples specifically showcase gesture movements. Some input images and audio come from TED, Pexels, and AIGC. The videos below highlight OmniHuman-1's ability to capture detailed hand and body gestures in various scenarios:
OmniHuman: More Portrait Cases
In addition to full-body and half-body animations, OmniHuman-1 also excels at generating realistic portrait videos. The examples below, derived from test samples in the CelebV-HQ dataset, showcase the model's ability to produce stunning head and facial animations:
OmniHuman: Compatibility with Video Driving
Due to OmniHuman's mixed condition training characteristics, it can support not only audio driving but also video driving to mimic specific video actions, as well as combined audio and video driving to control precise body parts. The following video demonstrates this advanced capability:
OmniHuman: Future Use Cases and Applications
The potential of OmniHuman-1 extends well beyond current demonstrations. Its innovative design opens up a multitude of future applications across various industries.
Expanding Horizons with OmniHuman
- Entertainment and Film Production: Revolutionizing character animation and reducing the need for manual motion capture.
- Video Game Development: Creating responsive and realistic avatars that enhance player immersion.
- Virtual Assistants and Social Media: Enabling dynamic, expressive digital personas for enhanced user engagement.
- Educational and Training Tools: Providing interactive visual content that can bring complex concepts to life through realistic human interactions.
Beyond Today: Looking Forward
As real-time motion capture and AI integration continue to evolve, OmniHuman-1 is poised to lead the next wave of digital transformation. Its ability to integrate multimodal data seamlessly could soon enable:
- Personalized Digital Experiences: Where users interact with avatars that mirror their own expressions and gestures.
- Real-Time Animation Synthesis: Allowing for instantaneous avatar responses in live-streaming and virtual reality environments.